|
Programming Taskbook |
|
|
||
|
Электронный задачник по программированию |
||||
|
© М. Э. Абрамян (Южный федеральный университет, Университет МГУ-ППИ в Шэньчжэне), 1998–2026 |


|
|
Выполнение заданий на обработку файловДанная страница содержит подробное описание процесса решения типовой задачи на обработку двоичных файлов с числовой информацией, а также примеры решения задач на обработку строковых и текстовых файлов. Двоичные файлы с числовой информацией: File48Особенности выполнения заданий на обработку файлов рассмотрим на примере задания File48. File48°. Даны три файла целых чисел одинакового размера с именами SA, SB, SC и строка SD. Создать новый файл с именем SD, в котором чередовались бы элементы исходных файлов с одним и тем же номером: A1, B1, C1, A2, B2, C2, ... . Создание программы-заготовки и знакомство с заданиемНапомним, что проект-заготовку для решения задания можно создать с помощью модуля PT4Load. Приведем текст функции Solve из файла File48.cpp, входящего в созданный проект (именно в эту функцию требуется ввести решение задания): [C/C++] void Solve()
{
Task("File48");
}
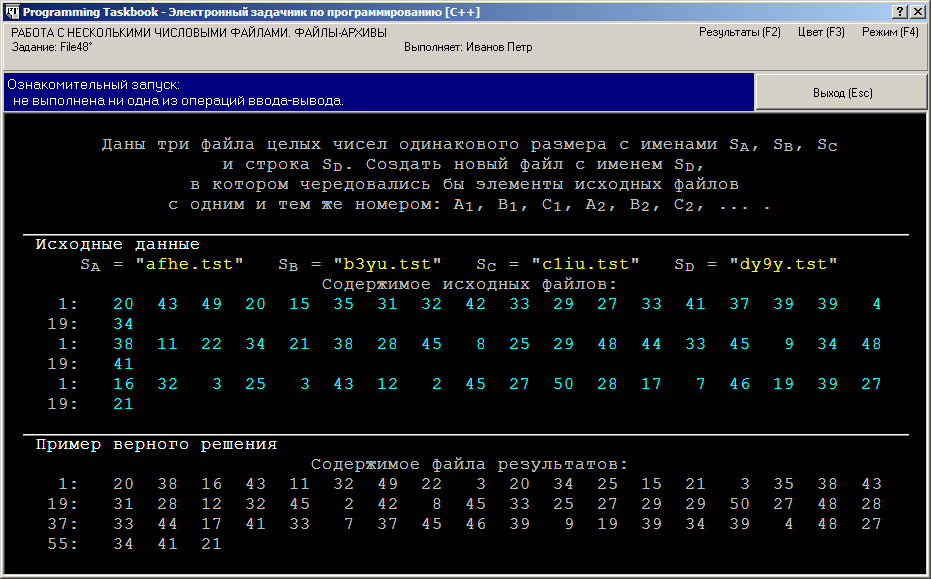
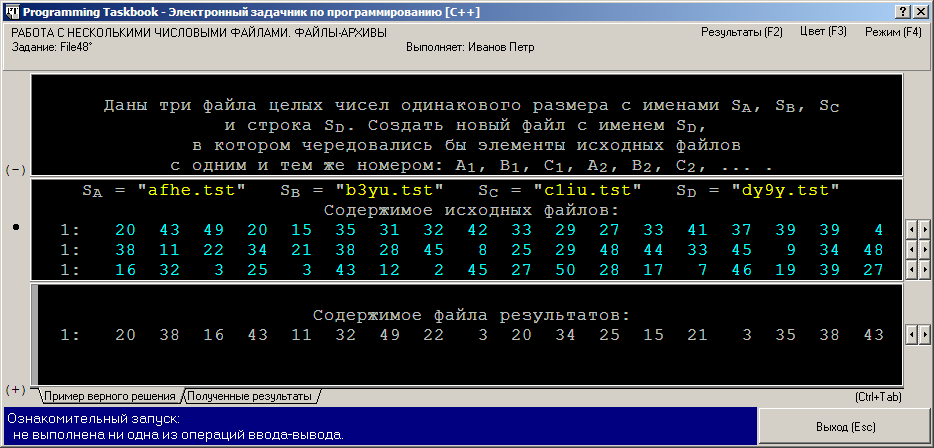
Функция Solve для языка C выглядит аналогичным образом. После запуска программы на экране появится окно задачника. На рисунке приведены два варианта представления окна — в режиме с динамической и с фиксированной компоновкой:
В первой строке раздела исходных данных указаны имена трех исходных файлов (SA, SB и SC) и одного результирующего (SD). В последующих строках раздела исходных данных показано содержимое исходных файлов. Элементы файлов отображаются бирюзовым цветом, чтобы подчеркнуть их отличие от обычных исходных данных (желтого цвета) и комментариев (светло-серого цвета). В режиме с фиксированной компоновкой для отображения содержимого каждого двоичного файла отводится по одной строке. Поскольку размер файлов, как правило, превышает количество элементов, которое может уместиться на одной экранной строке, в режиме с фиксированной компоновкой предусмотрена возможность прокрутки (листания) элементов файла с помощью мыши или клавиатуры. В режиме с динамической компоновкой на экране отображаются все элементы двоичных файлов, даже если для этого требуется использовать более одной экранной строки; при этом в начале каждой строки указывается порядковый номер первого элемента файла, приведенного в данной строке (элементы нумеруются от 1). Следует заметить, что при каждом запуске программы с учебным заданием исходные файлы создаются под новыми именами и заполняются новыми данными, а исходные и результирующие файлы, созданные при предыдущем запуске программы, удаляются с диска. Вернемся к нашей программе, только что запущенной на выполнение. Так как в ней не указаны операторы ввода-вывода, запуск программы считается ознакомительным, проверка решения не производится, а на экране отображается пример верного решения (в нашем случае это числа, которые должны содержаться в результирующем файле при правильном решении задачи). Ввод исходных данныхКак и при обсуждении задания на обработку строк, рассмотрим два варианта решений. Первый вариант, использующий функции из заголовочного файла <stdio.h> стандартной библиотеки C, подходит и для языка C, и для языка C++ (для языка C++ соответствующий заголовочный файл имеет вид <cstdio>). Во втором варианте мы применим особые возможности языка C++, связанные с файловыми потоками (определенными в заголовочном файле <fstream>). Напомним, что для подключения заголовочных файлов надо использовать директиву #include, например: [C] #include <stdio.h> [C++] #include <fstream> Напомним также, что к заготовке на языке C++ уже подключена директива using namespace std, благодаря которой не требуется указывать префикс std перед именами стандартных классов. В функцию Solve добавим фрагмент, позволяющий ввести имена исходных файлов и связать с этими именами соответствующие файловые переменные (или файловые потоки в C++). Для ввода имен файлов в программе на C достаточно использовать единственный символьный массив name из 13 символов, а в программе на C++ можно вообще обойтись без строковой переменной, используя функцию ввода GetString. Поскольку мы собираемся работать с четырьмя файлами, удобно предусмотреть массив из четырех файловых переменных (или файловых потоков): [C] Task("File48");
FILE *f[4];
for (int i = 0; i < 3; ++i)
{
char name[13];
GetS(name);
f[i] = fopen(name, "rb");
}
[C++] Task("File48");
fstream f[4];
for (int i = 0; i < 3; ++i)
f[i].open(GetString(), ios::in | ios::binary);
Мы намеренно ограничились тремя итерациями цикла, оставив непрочитанным имя результирующего файла. Считывание имен файлов в программе на C производится в одну и ту же переменную name, поскольку после связывания файла, имеющего имя name, с файловой переменной f[i] все остальные действия с данным файлом в нашей программе будут осуществляться с использованием переменной f[i], без обращения к имени файла. Запуск нового варианта программы уже не будет считаться ознакомительным, поскольку в программе выполняется ввод исходных данных. Так как имя результирующего файла осталось непрочитанным, этот вариант решения будет признан неверным и приведет к сообщению «Введены не все требуемые исходные данные. Количество прочитанных данных: 3 (из 4)». Изменим функцию Solve, заменив в заголовке цикла число 3 на 4, и вновь запустим программу. Теперь все данные, необходимые для выполнения задания, в программу введены. Однако задание не выполнено, поскольку результирующий файл не создан. Начиная с версии 4.15, в этой ситуации выводится сообщение (на светло-синем фоне): «Запуск с правильным вводом данных: все требуемые исходные данные введены, результирующий файл не создан» (в предыдущих версиях сообщение имело вид «Результирующий файл не найден»). Отметим, что при выполнении последней, четвертой, итерации цикла попытка открыть файл приведет к ошибке времени выполнения, поскольку для этого файла, как и для всех предыдущих, указан режим открытия для чтения ("r" или ios::in), в то время как файл с указанным именем не существует. Однако такие ошибки в языках C и C++ не приводят к аварийному завершению программы. Создание пустого результирующего файлаДля того чтобы избежать ошибки, возникшей на предыдущем шаге выполнения задания, отсутствующий файл результатов следует открыть не для чтения, а для записи. Далее, после завершения работы с файлами, открытыми в программе, их необходимо закрыть функцией fclose (для C) или функцией-членом close (для C++). Добавим в функцию Solve соответствующие операторы: [C] Task("File48");
FILE *f[4];
for (int i = 0; i < 3; ++i)
{
char name[13];
GetS(name);
if (i < 3)
f[i] = fopen(name, "rb");
else
f[i] = fopen(name, "wb");
}
// Обработка файловых данных
for (int i = 0; i < 4; ++i)
fclose(f[i]);
[C++] Task("File48");
fstream f[4];
for (int i = 0; i < 3; ++i)
if (i < 3)
f[i].open(GetString(), ios::in | ios::binary);
else
f[i].open(GetString(), ios::out | ios::binary);
// Обработка файловых данных
for (i = 0; i < 4; i++)
f[i].close();
Комментарий «Обработка файловых данных» расположен в том месте программы, в котором можно выполнять операции ввода-вывода для всех четырех файлов: они уже открыты и еще не закрыты. При выполнении этого варианта программы результирующий файл будет
создан, однако останется пустым, т. е. не содержащим ни одного элемента.
Начиная с версии 4.15, в этом случае на информационной панели выводится сообщение (на светло-синем фоне):
«Запуск с правильным вводом данных: все требуемые данные введены, результирующий файл является
пустым» (в предыдущих версиях в этой ситуации на информационной панели выводилось сообщение
«Ошибочное решение», а в строке, которая должна содержать элементы
результирующего файла, отображался текст Таким образом, нам осталось реализовать фрагмент алгоритма, обеспечивающий ввод и вывод файловых данных. Использование неправильных типов для файловых элементовВо всех ранее рассмотренных вариантах программы мы не использовали операции ввода-вывода для файлов. Поэтому тип файловых элементов нас не интересовал. Однако при чтении данных из файла (и при их записи в файл) очень важно правильно указывать тип файловых элементов. Чтобы продемонстрировать это на примере нашей программы, попытаемся прочесть из исходных файлов по одному элементу вещественного типа и запишем прочитанные элементы в файл результатов. Для этого заменим комментарий «Обработка файловых данных» на следующий фрагмент: [C] for (int i = 0; i < 3; ++i)
{
double x;
fread(&x, sizeof(x), 1, f[i]);
fwrite(&x, sizeof(x), 1, f[3]);
}
[C++] for (int i = 0; i < 3; ++i)
{
double x;
f[i].read((char *)&x, sizeof(x));
f[3].write((char *)&x, sizeof(x));
}
Данный фрагмент обеспечивает считывание одного вещественного элемента для каждого из трех исходных файлов и запись этих элементов в результирующий файл (в требуемом порядке). Подчеркнем, что мы неправильно указали тип файловых элементов; тем не менее, компиляция программы пройдет успешно, а после ее запуска не возникнет ошибок времени выполнения. Результат работы программы будет неожиданным: судя по экранной строке с содержимым результирующего файла, в него будут записаны не три, а шесть элементов, по два начальных элемента из каждого исходного файла. Объясняется это тем, что считывание из файла и последующая запись в файл одного «вещественного элемента» фактически приводит к считыванию и записи блока данных размером 8 байтов, содержащего два последовательных целочисленных элемента исходного файла. Итак, мы выяснили, что ошибки, связанные с несоответствием типов файловых элементов, не выявляются при компиляции и не всегда приводят к ошибкам времени выполнения. Это следует иметь в виду, и при появлении «странных» результирующих данных начинать поиск ошибки с проверки типов файловых элементов. Для исправления данной ошибки достаточно изменить описание переменной x: [C/C++] int x; Запустив исправленную программу, мы получим все еще неверный, но вполне «понятный» результат: созданный файл будет содержать три элемента, совпадающих с начальными элементами исходных файлов. Правильное решение, его тестирование и просмотр результатовПриведем, наконец, правильное решение задачи File48: [C] Task("File48");
FILE *f[4];
for (int i = 0; i < 4; ++i)
{
char name[13];
GetS(name);
if (i < 3)
f[i] = fopen(name, "rb");
else
f[i] = fopen(name, "wb");
}
while (ungetc(fgetc(f[0]), f[0]) != EOF)
for (int i = 0; i < 3; ++i)
{
int x;
fread(&x, sizeof(x), 1, f[i]);
fwrite(&x, sizeof(x), 1, f[3]);
}
for (int i = 0; i < 4; ++i)
fclose(f[i]);
[C++] Task("File48");
fstream f[4];
for (int i = 0; i < 4; i++)
if (i < 3)
f[i].open(GetString(), ios::in | ios::binary);
else
f[i].open(GetString(), ios::out | ios::binary);
while (f[0].peek() != EOF)
for (int i = 0; i < 3; ++i)
{
int x;
f[i].read((char *)&x, sizeof(x));
f[3].write((char *)&x, sizeof(x));
}
for (int i = 0; i < 4; i++)
f[i].close();
От предыдущего варианта данное решение отличается добавлением цикла while, который обеспечивает считывание всех элементов из исходных файлов (напомним, что по условию задания все исходные файлы имеют одинаковый размер) и запись их в результирующий файл в нужном порядке. В условии цикла while для языка C++ использован метод peek(), который возвращает код очередного символа из файла, не считывая данный символ (и, следовательно, не перемещая файловый указатель), причем если достигнут конец файла, то данный метод возвращает особое значени EOF (равное –1). Поскольку в стандартной библиотеке C нет функции, аналогичной методу peek, в варианте решения для языка C была использована комбинация функций fgetc и ungetc. Функция fgetc считывает и возвращает очередной символ из файла (или константу EOF, если достигнут конец файла). Функция ungetc отправляет обратно в файл указанный символ и, кроме того, возвращает его значение. Таким образом, комбинация этих функций позволяет узнать значение очередного символа в файле, не выполняя его считывание (и, кроме того, она возвращает значение EOF, если очередной символ отсутствует). В программе на языке C можно определить макрос, выполняющий действия, аналогичные действиям метода peek в языке C++ (обратите внимание на то, что определения макросов не следует завершать символом "точка с запятой"): [C] #define peek(f) ungetc(fgetc(f), f) При наличии такого макроса условие цикла while можно записать короче: [C] while (peek(f[0]) != EOF) После запуска этого варианта программы и успешного прохождения 5 тестов мы получим сообщение «Задание выполнено!». Нажав клавишу [F2], мы можем вывести на экран окно результатов, в котором будут перечислены все наши попытки решения задачи: File48 c24/03 12:15 Ознакомительный запуск. File48 c24/03 12:16 Введены не все требуемые исходные данные. File48 c24/03 12:17 Запуск с правильным вводом данных.--2 File48 c24/03 12:19 Ошибочное решение.--2 File48 c24/03 12:21 Задание выполнено! Строковые и текстовые файлы: File67, Text21В данном пункте описываются особенности выполнения заданий на обработку строковых файлов (т. е. двоичных файлов, содержащих строковые данные), а также текстовых файлов, содержащих строки различной длины, оканчивающиеся маркерами конца строки. Двоичные строковые файлыВ качестве примера задания на строковые файлы рассмотрим задание File67. File67°. Дан строковый файл, содержащий даты в формате «день/месяц/год», причем под день и месяц отводится по две позиции, а под год — четыре (например, «16/04/2001»). Создать два файла целых чисел, первый из которых содержит значения дней, а второй — значения месяцев для дат из исходного строкового файла (в том же порядке). При выполнении заданий на языках C и C++ предполагается, что элементы в строковом файле всегда занимают 80 байтов, независимо от длины содержащейся в нем строки (фактическая длина строки определяется по положению завершающего ее нулевого символа '\0'). Поэтому для операций ввода-вывода, связанных со строковыми файлами, необходимо использовать переменные типа char[80]. При открытии строковых файлов, как и при открытии других двоичных файлов, необходимо указывать атрибут "b" (для C) или ios::binary (для C++). Для чтения строк из строкового файла, как и для чтения данных из двоичных файлов других типов, следует использовать функцию fread (для С) или метод read (для C++). Сразу приведем правильное решение задачи File67, учитывающее отмеченные выше особенности строковых файлов (в варианте решения для C++ используются файловые потоки типов ifstream и ofstream, первый из которых открывает файл только на чтение, а второй — только на запись): [C] // В начале программы надо указать директивы
// #include <stdio.h>, #include <string.h> и #include <stdlib.h>
Task("File67");
char name[13];
GetS(name);
FILE *f = fopen(name, "rb");
GetS(name);
FILE *f1 = fopen(name, "wb");
GetS(name);
FILE *f2 = fopen(name, "wb");
char x[80];
while (fread(x, 80, 1, f))
{
char a[3];
strncpy(a, x, 2);
int n = atoi(a);
fwrite(&n, sizeof(n), 1, f1);
strncpy(a, &x[3], 2);
n = atoi(a);
fwrite(&n, sizeof(n), 1, f2);
}
fclose(f);
fclose(f1);
fclose(f2);
[C++] // В начале программы надо указать директивы
// #include <fstream>, #include <cstring> и #include <cstdlib>
Task("File67");
ifstream f(GetString(), ios_base::binary);
ofstream f1(GetString(), ios_base::binary),
f2(GetString(), ios_base::binary);
while (f.peek() != -1)
{
char x[80], a[3];
f.read((char *)&x, sizeof(x));
strncpy(a, x, 2);
int n = atoi(a);
f1.write((char *)&n, sizeof(n));
strncpy(a, &x[3], 2);
n = atoi(a);
f2.write((char *)&n, sizeof(n));
}
f.close();
f1.close();
f2.close();
В программе на языке C мы использовали следующую особенность функций fread и fwrite: каждая из них возвращает количество успешно обработанных (т. е. прочитанных или записанных) файловых элементов. Таким образом, мы можем совместить действия по чтению очередного файлового элемента с проверкой их успешности, если вызвать функцию fread в заголовке цикла while. Заметим, что метод read для языка C++ тоже можно использовать аналогичным образом, помещая его в заголовок цикла (хотя его возвращаемое значение имеет совершенно другой смысл). Текстовые файлыВ качестве примера задания на текстовые файлы рассмотрим задание Text21. Text21°. Дан текстовый файл, содержащий более трех строк. Удалить из него последние три строки. Поскольку текстовые файлы, в отличие от двоичных файлов, нельзя открыть одновременно на чтение и на запись, для изменения текстового файла необходимо воспользоваться вспомогательным файлом. Во вспомогательный файл записываются необходимые результирующие данные, после чего исходный файл удаляется с диска, а имя вспомогательного файла заменяется на имя исходного. Далее, поскольку строки, содержащиеся в текстовом файле, могут иметь различную длину, для определения числа строк необходимо последовательно считать из файла все его строки. Заметим, что для чтения данных из текстовых файлов следует использовать не функцию fread или метод read (как для двоичных строковых файлов), а функцию fgets (для языка C) или один из вариантов функций getline (для языка C++). Для записи строк в текстовый файл надо использовать функцию fputs (для языка С), а в случае языка C++ удобно применять операцию <<. При выполнении заданий можно считать, что длина любой строки в текстовом файле не превосходит 79 символов. Приведем решение задачи Text21, учитывающее отмеченные выше особенности текстовых файлов: [C] // В начале программы надо указать директиву
// #include <stdio.h>
Task("Text21");
char name1[13];
GetS(name1);
char *name2 = "$$.tmp";
FILE *f1 = fopen(name1, "r");
FILE *f2 = fopen(name2, "w");
char s[80];
int n = 0;
while (fgets(s, 80, f1))
++n;
rewind(f1);
for (int i = 0; i < n - 3; ++i)
{
fgets(s, 80, f1);
fputs(s, f2);
}
fclose(f1);
fclose(f2);
remove(name1);
rename(name2, name1);
[C++] // В начале программы надо указать директивы
// #include <fstream>, #include <string> и #include <cstdio>
Task("Text21");
string name1 = GetString(), name2 = "$$.tmp";
ifstream f1(name1);
ofstream f2(name2);
string s;
int n = 0;
while (f1.peek() != -1)
{
getline(f1, s);
n++;
}
f1.clear();
f1.seekg(0);
for (int i = 0; i < n - 3; ++i)
{
getline(f1, s);
f2 << s << endl;
}
f1.close();
f2.close();
remove(name1.c_str());
rename(name2.c_str(), name1.c_str());
В программе на C обратите внимание на вызов функции rewind(f1), которая сбрасывает индикатор конца файла (и индикатор ошибки) и переводит файловый указатель в начало файла. В программе на C++ аналогичные действия обеспечиваются двумя методами: clear и seekg. В частности, метод clear возвращает поток ввода-вывода из состояния «достигнут конец файла» или из состояния ошибки в стандартное состояние; если не вызвать данный метод, то все последующие попытки чтения из потока будут оканчиваться неудачей (и в результате полученный файл будет содержать лишь пустые строки). Приведенный выше вариант решения является неэффективным, поскольку требует двух просмотров исходного файла f1: первый — для определения его размера, который записывается в переменную n, второй — для создания вспомогательного файла f2, содержащего все строки исходного файла, кроме трех последних. Задание Text21 можно выполнить и за один просмотр исходного файла, если воспользоваться следующим наблюдением: строка должна быть записана во вспомогательный файл, если после нее в исходном файле находятся по крайней мере три строки. Таким образом, записывать очередную строку во вспомогательный файл следует только после считывания из исходного файла трех следующих за ней строк. Благодаря такому упреждающему считыванию необходимость в предварительном определении размера исходного файла отпадает. Для хранения строк, которые уже считаны из исходного файла, но еще не записаны во вспомогательный файл, удобно использовать массив из трех строковых элементов. Приведем программу, реализующую описанный выше эффективный однопроходный алгоритм решения задачи: [C] // В начале программы надо указать
// директиву #include <stdio.h>
// и макроопределение #define peek(f) ungetc(fgetc(f), f)
Task("Text21");
char name1[13];
GetS(name1);
char *name2 = "$$.tmp";
FILE *f1 = fopen(name1, "r");
FILE *f2 = fopen(name2, "w");
char s[3][80];
int n = 0;
for (int i = 0; i < 3; ++i)
fgets(s[i], 80, f1);
while (peek(f1) != EOF)
{
fputs(s[n], f2);
fgets(s[n], 80, f1);
n = (n + 1) % 3;
}
fclose(f1);
fclose(f2);
remove(name1);
rename(name2, name1);
[C++] // В начале программы надо указать директивы
// #include <fstream>, #include <string> и #include <cstdio>
Task("Text21");
string name1 = GetString(), name2 = "$$.tmp";
ifstream f1(name1);
ofstream f2(name2);
string s[3];
int n = 0;
for (int i = 0; i < 3; ++i)
getline(f1, s[i]);
while (f1.peek() != -1)
{
f2 << s[n] << endl;
getline(f1, s[n]);
n = (n + 1) % 3;
}
f1.close();
f2.close();
remove(name1.c_str());
rename(name2.c_str(), name1.c_str());
|
|
|
Разработка сайта: |
Последнее обновление: |