|
|
Пересылка сообщений между двумя процессами:
MPIBegin17
Рассмотрим задание, связанное с пересылкой сообщений
между различными процессами параллельной программы, и познакомимся
с особенностями используемых для этого функций MPI.
MPIBegin17.
В каждом процессе дано вещественное число.
Переслать число из главного процесса во все подчиненные процессы, а
все числа из подчиненных процессов — в главный, и вывести
в каждом процессе полученные числа (в главном процессе числа
выводить в порядке возрастания рангов переславших их процессов).
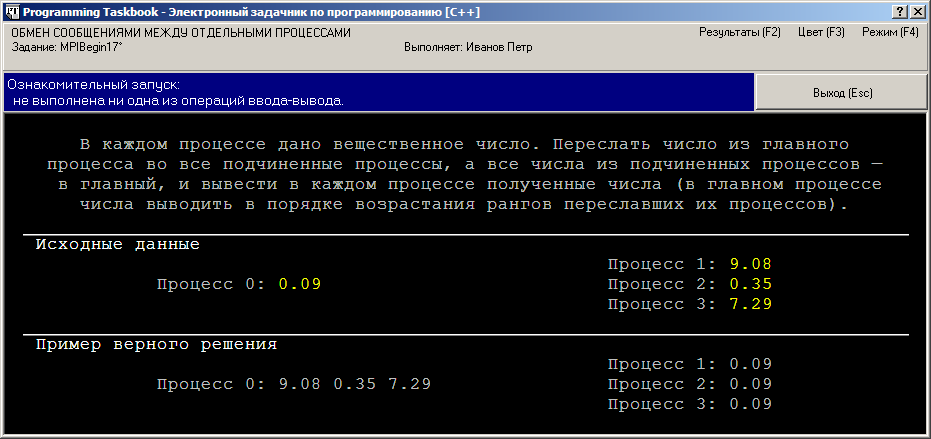
Создадим проект-заготовку для выполнения этого задания и запустим
полученную программу. Появившееся на экране окно задачника будет
иметь следующий вид:
Для чтения исходных данных нам будет достаточно использовать
единственную переменную вещественного типа, поскольку в каждом процессе
дано только одно вещественное число.
Исходные данные надо переслать в другие процессы параллельной
программы. Для этого в библиотеке MPI имеется много различных
функций, однако чаще всего для пересылки данных между двумя
процессами используется пара функций MPI_Send и MPI_Recv. Первая из
указанных функций вызывается передающим процессом и определяет,
какому процессу и какие данные он собирается переслать, а вторая
функция вызывается принимающим процессом; в ней указываются
процесс-отправитель и переменная-буфер, в которую будут записаны
полученные от него данные.
Вначале займемся приемом и пересылкой данных для подчиненных
процессов, не реализуя пока действия, которые надо выполнить в главном
процессе.
Добавим в программу следующий фрагмент кода (в программе на
языке Pascal надо дополнительно описать переменную a вещественного типа и
переменную s типа MPI_Status):
[C++]
double a;
MPI_Status s;
if (rank > 0)
{
MPI_Recv(&a, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD, &s);
pt << a;
pt >> a;
MPI_Send(&a, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD);
}
[Pascal]
if rank > 0 then
begin
MPI_Recv(@a, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD, s);
PutR(a);
GetR(a);
MPI_Send(@a, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD);
end;
Обратите внимание на то, что в качестве первого параметра как для языка
С++, так и для языка Pascal указывается адрес той
переменной, которая содержит (или должна принять) пересылаемые
данные.
Мы намеренно расположили вызов MPI-функций в
«неестественном» порядке (вначале чтение данных,
полученных из процесса 0, а затем отправка этому процессу своих
данных). Это позволит нам познакомиться с одной из распространенных
ошибок, возникающих при выполнении параллельных программ.
Запустим нашу программу. Через 5–10 с после появления
консольного окна с информацией о том, что программа запущена в
параллельном режиме, на экране появится окно задачника с сообщением
об ошибке в подчиненных процессах:
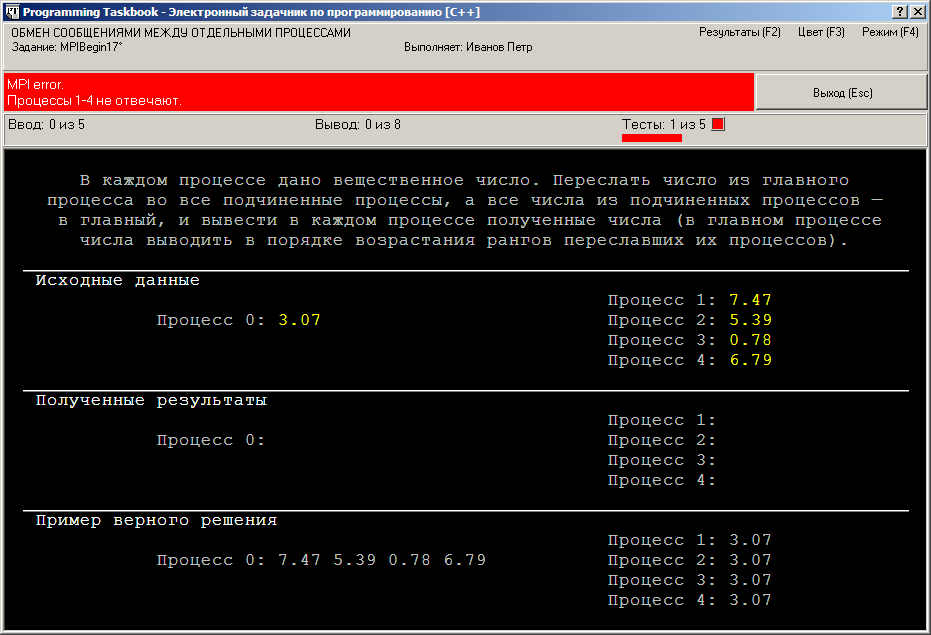
Сообщение об ошибке вида «MPI error. Процессы 1–4
не отвечают» означает, что главный процесс нашей
параллельной программы не смог в течение определенного времени
(5–10 с) «связаться» с подчиненными процессами с
целью получить от них информацию о введенных и выведенных в них
данных. Причем, как следует из второй строки сообщения, ошибка
возникла при попытке связаться со всеми подчиненными процессами
(которых при данном запуске программы было четыре).
Причина ошибки — в функции MPI_Recv. Вызов этой функции
приведет к тому, что процесс-получатель перейдет в режим ожидания
данных от процесса-отправителя (в нашем случае — процесса
ранга 0), и не продолжит выполнение программы до тех пор, пока
данные не будут им получены (так работает блокирующий режим
получения сообщения, который реализует функция MPI_Recv). А
поскольку в нашей программе не предусмотрено (пока) посылки
сообщения от процесса ранга 0, ожидание в каждом из подчиненных
процессов будет длиться вечно (точнее, пока их выполнение не будет
прекращено «насильственным образом»). Это пример
зависания параллельной программы, возникающего обычно из-за
того, что один или несколько процессов блокируются в ожидании данных,
которые им не посланы.
Заметим, что при закрытии окна задачника консольное окно останется
на экране. В самом деле, консольное окно управляется программой
MPIRun, которая завершает работу только при завершении всех процессов
запущенной параллельной программы, а в данном случае завершился
только главный процесс (подчиненные процессы остаются
заблокированными). Для завершения программы MPIRun и закрытия
консольного окна необходимо нажать несколько раз комбинацию клавиш
[Ctrl]+[C] или [Ctrl]+[Break].
Итак, мы познакомились с ситуацией, когда один или несколько
подчиненных процессов оказываются заблокированными. Такая же
«неприятность» может произойти и с главным процессом.
Дополним нашу программу фрагментом, связанным с главным процессом,
причем в этом фрагменте также организуем вызов MPI-функций в
неестественном порядке — вначале прием, затем отправка данных (в
программе на языке Pascal надо дополнительно описать переменную i целого
типа и удалить символ «;» в конце предыдущего фрагмента):
[C++]
else
{
for (int i = 1; i < size; ++i)
{
MPI_Recv(&a, 1, MPI_DOUBLE, i, 0, MPI_COMM_WORLD, &s);
pt << a;
}
pt >> a;
for (int i = 1; i < size; ++i)
MPI_Send(&a, 1, MPI_DOUBLE, i, 0, MPI_COMM_WORLD);
}
[Pascal]
else
begin
for i := 1 to size - 1 do
begin
MPI_Recv(@a, 1, MPI_DOUBLE, i, 0, MPI_COMM_WORLD, s);
PutR(a);
end;
GetR(a);
for i := 1 to size - 1 do
MPI_Send(@a, 1, MPI_DOUBLE, i, 0, MPI_COMM_WORLD);
end;
Если запустить эту программу, то после появления консольного окна
можно ожидать сколько угодно, однако окно задачника на экране не
появится. Это связано с тем, что заблокированным оказался главный
процесс нашей параллельной программы: перед отображением окна
задачника главный процесс должен выполнить тот фрагмент программы,
который разработан для него учащимся, а в нашем случае этот фрагмент
привел к блокировке. Поэтому главный процесс просто не дошел до того
места программы, в котором выполняется вывод окна задачника на экран.
Если в течение 15–20 с окно задачника не появилось, то можно
считать, что произошло зависание главного процесса. В такой ситуации,
как и в ситуации, описанной ранее, необходимо явным образом прервать
выполнение параллельной программы, нажав несколько раз
[Ctrl]+[C] или [Ctrl]+[Break].
Для исправления нашей программы достаточно хотя бы в одном из
приведенных выше двух фрагментов изменить порядок вызова процедур
MPI_Send и MPI_Recv. Например, это можно сделать в первом фрагменте:
[C++]
if (rank > 0)
{
pt >> a;
MPI_Send(&a, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD);
MPI_Recv(&a, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD, &s);
pt << a;
}
[Pascal]
if rank > 0 then
begin
GetR(a);
MPI_Send(@a, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD);
MPI_Recv(@a, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD, s);
PutR(a);
end
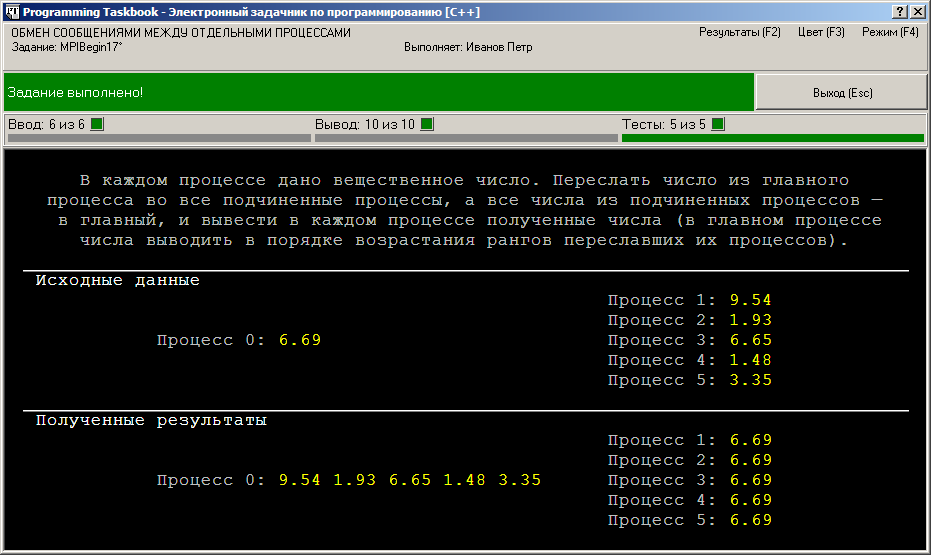
После требуемого количества тестовых испытаний программы будет выведено сообщение о том, что задание выполнено:
Полученную программу можно упростить, если в разделе else
воспользоваться вспомогательной вещественной переменной b для
получения данных из подчиненных процессов. Это позволит разместить
оператор ввода (pt >> a для C++, GetR(a)
для Pascal) перед последним условным оператором,
а также даст возможность выполнить все действия в разделе else в единственном цикле.
Приведем соответствующий вариант решения:
[C++]
void Solve()
{
Task("MPIBegin17");
int flag;
MPI_Initialized(&flag);
if (flag == 0)
return;
int rank, size;
MPI_Comm_size(MPI_COMM_WORLD, &size);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
double a;
MPI_Status s;
pt >> a;
if (rank > 0)
{
MPI_Send(&a, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD);
MPI_Recv(&a, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD, &s);
pt << a;
}
else
for (int i = 1; i < size; ++i)
{
double b;
MPI_Recv(&b, 1, MPI_DOUBLE, i, 0, MPI_COMM_WORLD, &s);
pt << b;
MPI_Send(&a, 1, MPI_DOUBLE, i, 0, MPI_COMM_WORLD);
}
}
[Pascal]
program MPIBegin17;
uses PT4, MPI;
var
flag, size, rank: integer;
a, b: real;
i: integer;
s: MPI_Status;
begin
Task('MPIBegin17');
MPI_Initialized(flag);
if flag = 0 then exit;
MPI_Comm_size(MPI_COMM_WORLD, size);
MPI_Comm_rank(MPI_COMM_WORLD, rank);
GetR(a);
if rank > 0 then
begin
MPI_Send(@a, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD);
MPI_Recv(@a, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD, s);
PutR(a);
end
else
for i := 1 to size - 1 do
begin
MPI_Recv(@b, 1, MPI_DOUBLE, i, 0, MPI_COMM_WORLD, s);
PutR(b);
MPI_Send(@a, 1, MPI_DOUBLE, i, 0, MPI_COMM_WORLD);
end;
end.
Заметим, что более эффективное решение этого задания можно
получить, используя коллективные операции пересылки данных.
|

