|
Programming Taskbook |
|
|
||
|
Электронный задачник по программированию |
||||
|
© М. Э. Абрамян (Южный федеральный университет, Университет МГУ-ППИ в Шэньчжэне), 1998–2026 |


|
|
Создание XML-документа: LinqXml10Задания группы LinqXml посвящены интерфейсу LINQ to XML, предназначенному для обработки документов XML. Интерфейс LINQ to XML включает, помимо дополнительных методов расширения, набор классов, связанных с различными компонентами XML. Этот набор образует объектную модель документа XML (XML Document Object Model — XML DOM), которую мы в дальнейшем для краткости будем обозначать X-DOM. Основные классы, входящие в X-DOM, а также понятия, используемые при работе с XML-документами, кратко описаны в преамбуле к группе LinqXml. Многие классы, входящие в X-DOM, имеют свойства, возвращающие различные последовательности; некоторые методы классов (в частности, их конструкторы) могут принимать последовательности в качестве своих параметров. Во всех ситуациях связанных с обработкой последовательностей, можно использовать базовые запросы LINQ, входящие в интерфейс LINQ to Objects и изученные нами при выполнении заданий из групп LinqBegin и LinqObj. Знакомство с возможностями LINQ to XML естественно начать с создания XML-документов. Этой теме посвящена первая подгруппа группы LinqXml. Рассмотрим последнее из заданий, входящих в эту подгруппу. LinqXml10°. Даны имена существующего текстового файла и создаваемого XML-документа. Создать XML-документ с корневым элементом root, элементами первого уровня line и инструкциями обработки (инструкции обработки являются дочерними узлами корневого элемента). Если строка текстового файла начинается с текста «data:», то она (без текста «data:») добавляется в XML-документ в качестве данных к очередной инструкции обработки с именем instr, в противном случае строка добавляется в качестве дочернего текстового узла в очередной элемент line. После создания с помощью программного модуля PT4Load проекта-заготовки для данного задания, автоматического запуска среды Visual Studio и загрузки в нее созданного проекта на экране будет отображен файл LinqXml10.cs. Приведем содержимое этого файла: // File: "LinqXml10"
using PT4;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.IO;
using System.Xml.Linq;
namespace PT4Tasks
{
public class MyTask : PT
{
// When solving tasks of the LinqXml group, the following
// additional methods defined in the taskbook are available:
// (*) Show() and Show(cmt) (extension methods) - debug output
// of a sequence, cmt - string comment;
// (*) Show(e => r) and Show(cmt, e => r) (extension methods) -
// debug output of r values, obtained from elements e
// of a sequence, cmt - string comment.
public static void Solve()
{
Task("LinqXml10");
}
}
}
Подобно ранее рассмотренным заготовкам, создаваемым для заданий
групп LinqBegin и LinqObj, этот файл содержит набор директив Заметим, что список директив В созданной заготовке отсутствуют дополнительные методы для
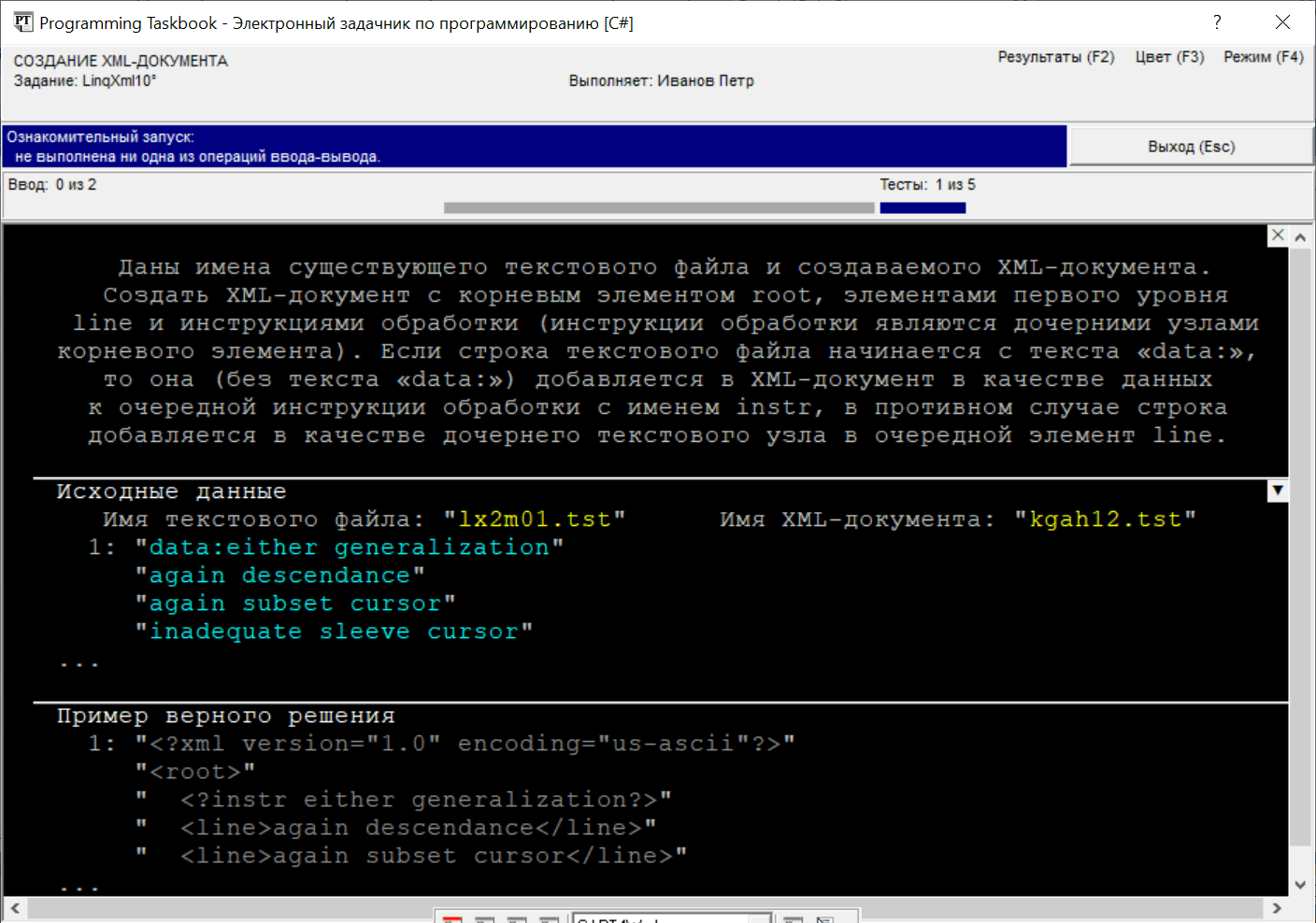
ввода-вывода последовательностей (подобные методам После запуска созданной программы-заготовки мы увидим на экране окно задачника, содержащее формулировку задания, а также пример исходных данных и правильных результатов:
Хотя файловые данные на приведенном рисунке отображаются в
сокращенном виде, указанные фрагменты демонстрируют все особенности
этих данных. В исходном текстовом файле содержатся строки,
представляющие собой наборы слов, причем некоторые строки
начинаются с текста «data:» (на рисунке этот текст содержит первая
строка); результирующий файл содержит XML-документ в кодировке
«us-ascii», включающий корневой элемент Элемент XML-документа обязательно имеет имя; он может быть
представлен в виде парных тегов вида Инструкция обработки является особым компонентом XML-документа,
который заключается в скобки вида Данные для инструкций Как уже было отмечено, исходную строковую последовательность
проще всего получить с помощью метода var a = File.ReadLines(GetString()); Для создания как самого XML-документа, так и его компонентов,
следует использовать конструкторы соответствующих классов. При
выполнении данного задания нам потребуются следующие классы,
входящие в X-DOM: Важной особенностью конструкторов классов В качестве примера функционального конструирования XML-документа
приведем фрагмент, который по последовательности строк XDocument d = new XDocument(
new XDeclaration(null, "us-ascii", null),
new XElement("root",
a.Select(e => new XElement("line", e))));
В этом фрагменте вначале вызывается конструктор класса
Примечание. При определении содержимого в конструкторе класса
В приведенном фрагменте не обрабатываются особым образом строки исходной последовательности, начинающиеся с текста «data:» (которые надо преобразовывать не в элементы, а в инструкции обработки). Этот недочет мы исправим позже. Осталось сохранить полученный XML-документ под требуемым
именем. Для этого достаточно использовать метод d.Save(GetString()); При вызове этого метода не требуется дополнительно указывать
используемую кодировку, поскольку она была ранее указана в объявлении
XML-документа. Заметим также, что метод
Примечание. При выполнении заданий возможность автоматического
форматирования XML-документа оказывается очень полезной, так как
она упрощает анализ полученного XML-документа и его сравнение с
«правильным» образцом. В ситуации, когда программа генерирует
XML-документ, не предназначенный для непосредственного
просмотра человеком, можно отключить возможность
форматирования, указав в методе Можно получить текстовое представление XML-документа, не
сохраняя его в файле; для этого достаточно вызвать для объекта типа
Метод Объединяя указанные выше операторы, получаем первый (пока еще не вполне правильный) вариант решения: public static void Solve()
{
Task("LinqXml10");
var a = File.ReadLines(GetString());
XDocument d = new XDocument(
new XDeclaration(null, "us-ascii", null),
new XElement("root",
a.Select(e => new XElement("line", e))));
d.Save(GetString());
}
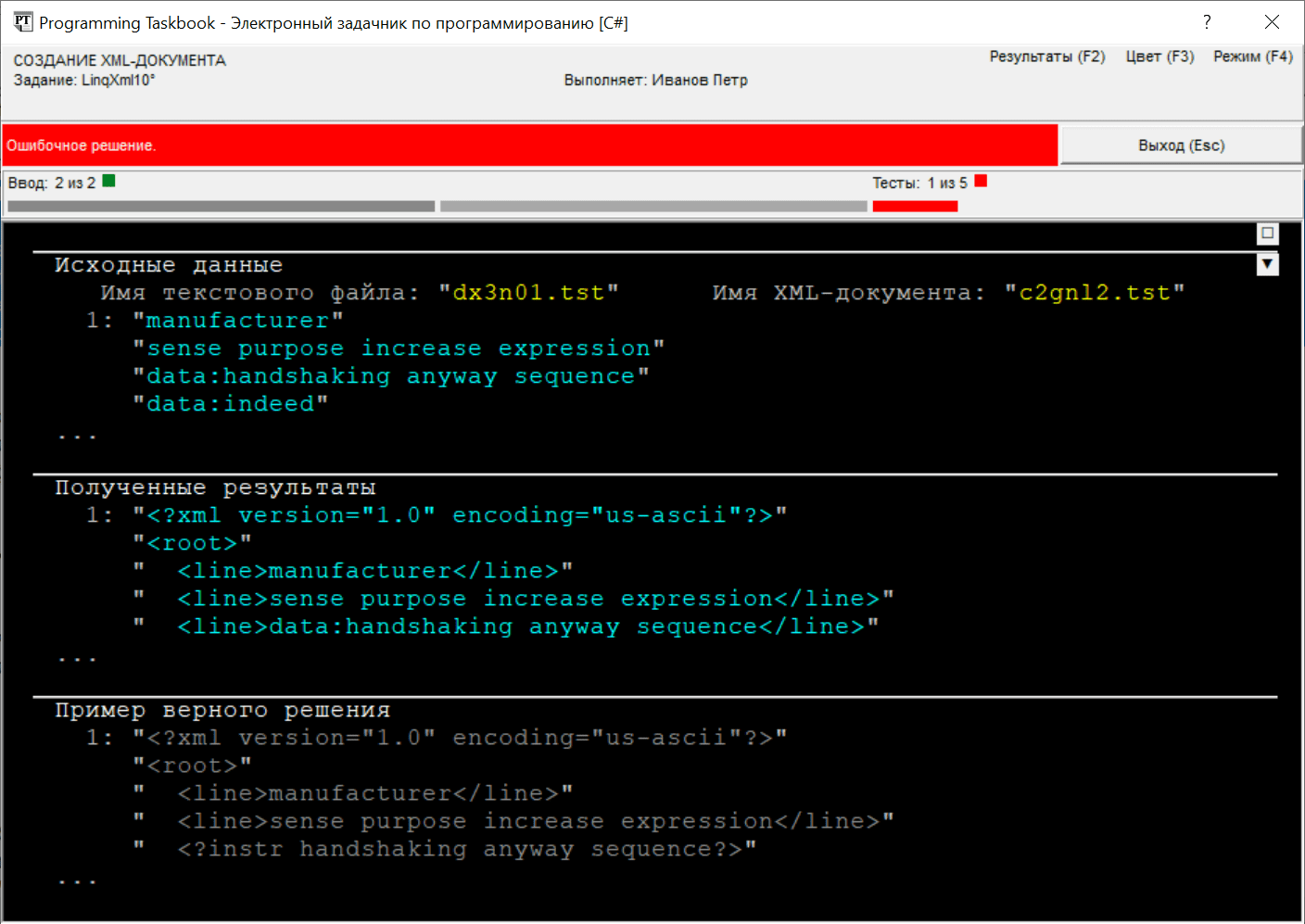
При запуске программы в окне будет выведено сообщение об ошибочном решении (для уменьшения размеров окна в нем скрыт раздел с формулировкой задания):
Для получения XML-документа, соответствующего условиям задачи,
надо при создании документа e => e.StartsWith("data:") ?
new XProcessingInstruction("instr", e.Substring(5)) :
new XElement("line", e)
При создании инструкции обработки в качестве ее данных
указывается подстрока строки Однако при попытке откомпилировать полученную программу будет
выведено сообщение об ошибке компиляции. Ошибка заключается в том,
что по приведенному лямбда-выражению нельзя определить тип
элементов возвращаемой последовательности (часть элементов будет
иметь тип e => e.StartsWith("data:") ?
new XProcessingInstruction("instr", e.Substring(5)) :
new XElement("line", e) as XNode
Примечание. Операция Вместо типа Подчеркнем, что приведение типа не изменяет
фактический тип элементов последовательности, оно лишь обеспечивает
единообразную интерпретацию всех этих элементов как XML-узлов, давая тем самым
компилятору возможность определить тип получаемой
последовательности (в нашем случае Приведем окончательный вариант решения: public static void Solve()
{
Task("LinqXml10");
var a = File.ReadLines(GetString());
XDocument d = new XDocument(
new XDeclaration(null, "us-ascii", null),
new XElement("root",
a.Select(e => e.StartsWith("data:") ?
new XProcessingInstruction("instr", e.Substring(5)) :
new XElement("line", e) as XNode)));
d.Save(GetString());
}
После пяти тестовых испытаний программы мы получим сообщение о том, что задание выполнено.
|
|
|
Разработка сайта: |
Последнее обновление: |